Two weekends ago, my Neurotech friends and I got together and decided to replicate an article we saw presented at the BCI conference: Improving Memory Performance Using a Wearable BCI . Since they use an Emotiv headset, we thought it should be possible to get similar results (or maybe even better) with an OpenBCI headset.
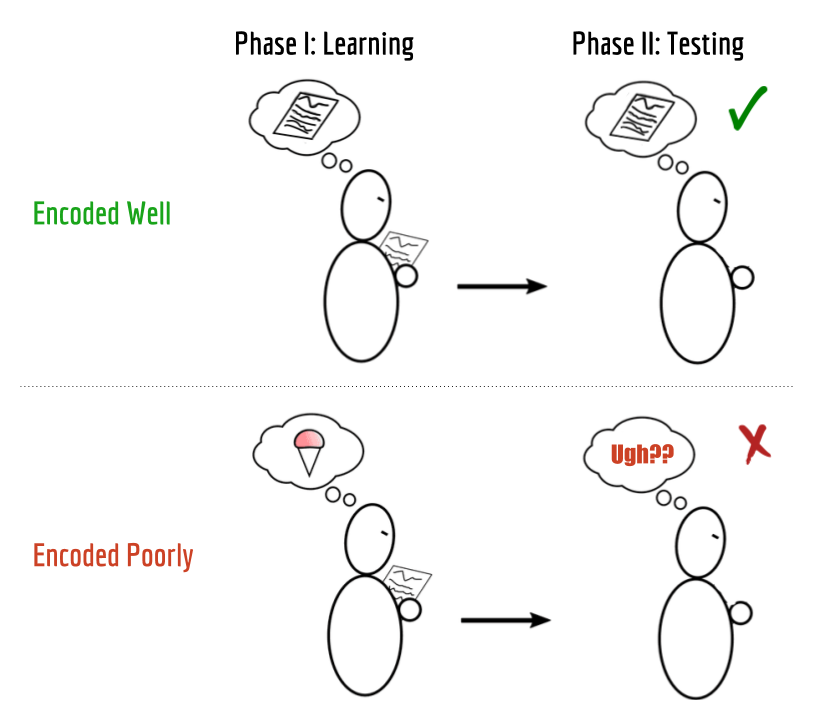
The basic idea is that when you're presented with some fact, you may or may not be in the right state of mind to remember it. At one time, you might be completely focused and be able to recall the fact precisely at a later time. Many times though, you get distracted (by ice cream or something) and you have no idea what you read or heard for the last 5 minutes.
What if we could automatically detect whether the memory is encoded based on brainwaves at that time? (It turns out there's a whole field about this!) If so, we could improve the flashcard system Anki by showing the cards we think you'll forget again earlier.
So we did it! We successfully recorded data using the OpenBCI and got some initial results.
Making an experiment like this from beginning to end might be daunting, so I've documented all our steps in as much detail as possible.
Before we begin, all our code is open-source and you can find it here:
https://github.com/zhannar/anki-eeg
Though the README file for the code is decent, I’ll describe the experiment in even more detail below.
Experiment
Start by attaching the OpenBCI electrodes to the participant's head

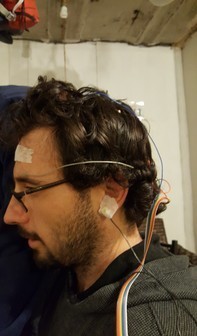
Our setup is similar to the getting started tutorial from OpenBCI. We also used a combination of Ten20 conductive paste and cup electrodes, and stuck each on the participant's scalp. Just as in the tutorial, we placed the SRB2 reference electrode on one earlobe, and the BIAS reference electrode on the other earlobe.


As can be seen in the images above, the main difference with our setup is that we used all 8 electrodes. Our reference paper got the strongest results from parietal and occipital regions, so we placed most of our electrodes there. Most commercial headsets get data primarily from the prefrontal cortex. We also placed 1-2 electrodes there to cover our bases and hedge against missing out on potentially useful results.
Check connections using the OpenBCI processing sketch
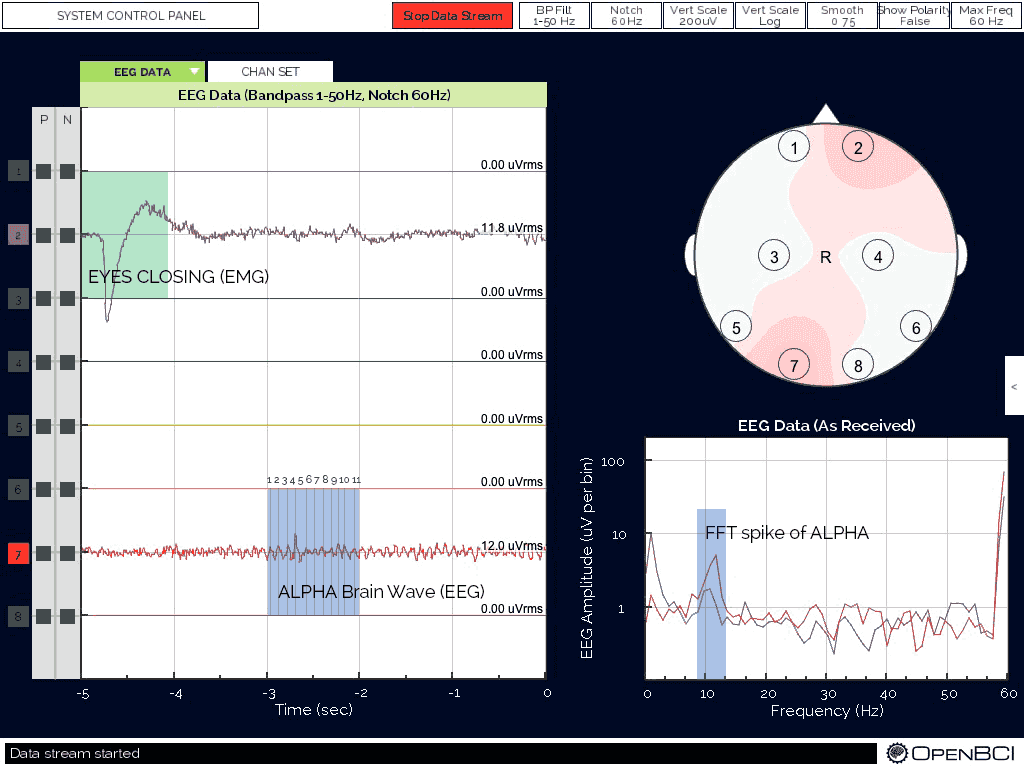
The OpenBCI tutorial, once again, walks you through how to get setup and run their processing sketch.
To check if you're getting EEG, we generally look for alpha waves and artifacts (eye blinks and jaw clench). You can see how those look in the picture above, from the OpenBCI tutorial.
If you don't check the EEG streams before the experiment, you may end up collecting just noise on some electrodes. In these checks, we often find that 1 or 2 electrodes are loose (possibly including the reference electrodes!), so we secure them properly.
Record positions of EEG according to 10-20 system
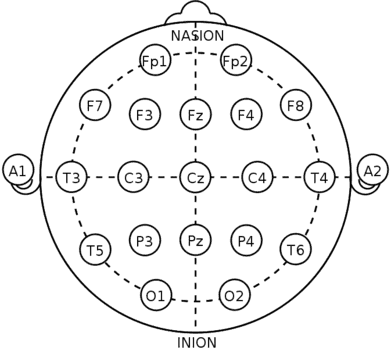
We took pictures of the participant’s head after applying the electrodes, then also recorded where we believed the electrodes were located referencing the 10-20 system diagram above. Knowing these positions allows us to connect our results back to the neuroscience.
In retrospect, a better way to run future experiment would be to standardize the positions first and then run multiple experiments with the same positions.
Present list of words and record

This is where we finally use the code we wrote!
You can run this from inside the repo to start the experiment:
cd paradigm
python encode.pyThis will start presenting the words using pygame. At the same time, it will start collecting EEG data into data/eegTIME.csv and the words displayed into data/wordsTIME.csv, where TIME is the Unix time at the start of recording.
After you've finished presenting the list of words, you can remove electrodes and unplug the OpenBCI.
Wait some time (we tended to wait around 1-5 minutes), then have your subject perform the recall test. To keep the experiment controlled, it's better to have each subject wait the same time (although we failed to do this in our few runs).
Test recall

After the participant has waited for some time, you can initiate the second part of the experiment (testing their recall) by running:
cd paradigm
python recognize.py ../data/words_TIME.csvwhere TIME is the Unix time of your previous recording.
This will generate a file in data/wordsTIMElabeled.csv, with an extra column "recognized", depending on whether the word was marked as recognized or not by the subject.
Analysis
You can finally move on to the really interesting part: the analysis!
Somehow I couldn’t document this in time, so you can check out the mildly documented IPython notebook.