There has been a lot of work in the past decade on quantifying animal movement and behavior. For the past 3 years, computer vision researchers have gathered together to review progress in this endeavor. This is the CV4Animals workshop.
I was excited to attend the CV4Animals 2021 workshop two years ago and I’m excited once again to attend CV4Animals 2023, this time in person for the first time.
It is much nicer to talk to people in person at posters and catch up with talk presenters afterwards. However, walking back and forth across the conference center multiple times to catch the talks then posters several times was quite taxing. I was impressed that so many people stayed for the workshop despite this journey. Such is dedication of animal vision scientists!

The workshop itself feels bigger and with more diverse computer vision problems and animals compared to 2021. While drafting this post, I realized I was covering much more work and themes than for my 2021 post. I wonder if I will have to cut down more dramatically for CV4Animals 2025.
So anyway, here are the themes I saw in the featured talks and in the poster session.
Vision in the wild
![]()
![]()
(Below) Examples of some images tracked in the wild. Both from Katija et al, 2021.
By far the biggest emphasis in the main sequence of talks was applying computer vision to images or videos of animals in the wild. Three of the keynote talks fell in this theme. Tanya Berger-Wolf (and her student Mohannad Elhamod) talked about network to map from images to a latent space that could be matched to known biological structures such as phylogeny.
Kakani Katija gave a memorable talk about the videos the Monterey Bay Aquarium Research Institute (MBARI) is collecting in the deep sea, plans for collecting more videos at large scale with autonomous underwater vehicles, and new initiatives for annotating all of this data. Along this line, Devis Tua talked about mapping coral reefs using a GoPro. They used photogrammetry along with some segmentation to remove fish, humans, and other things that are not coral reefs.
There were a few posters on this topic as well:
- Discovering Novel Biological Traits From Images Using Phylogeny-Guided Neural Networks
- Ecology at scale: Enabling real time learning for automated global reef monitoring in the (Reef)Cloud
- Robot Goes Fishing: Rapid, High-Resolution Biological Hotspot Mapping in Coral Reefs with Vision-Guided Autonomous Underwater Vehicles
- Scene and animal attributes retrieval from camera trap data with domain-adapted language-vision models
- Scaling whale monitoring using deep learning: A human-in-the-loop solution for analyzing aerial datasets
- Quantifying the movement, behaviour and environmental context of group-living animals using drones and computer vision
- Fine-grained image classification of microscopic insect pest species: Western Flower thrips and Plague thrips
These wild settings are really at the frontier of computer vision. “Foundation” models typically don’t work in these settings, as the videos may be in odd poses or lower quality (due to constraints of being in the field) and are often not in web datasets. Collecting in-depth annotated data is also time-consuming or sometimes impossible in these settings. The proposed ways to tackle these issues are to (1) use the known structures from biology, (2) rely on large scale human annotation, and (3) teach people how to collect better data at scale. These approaches make sense with the current technology.
I wonder if we can also make unsupervised approaches or synthetic data good and easy enough to make it a more standard approach in these novel environments. There may be ways to fine-tune the large models for these environments while still taking advantage of general vision priors.
Unsupervised approaches
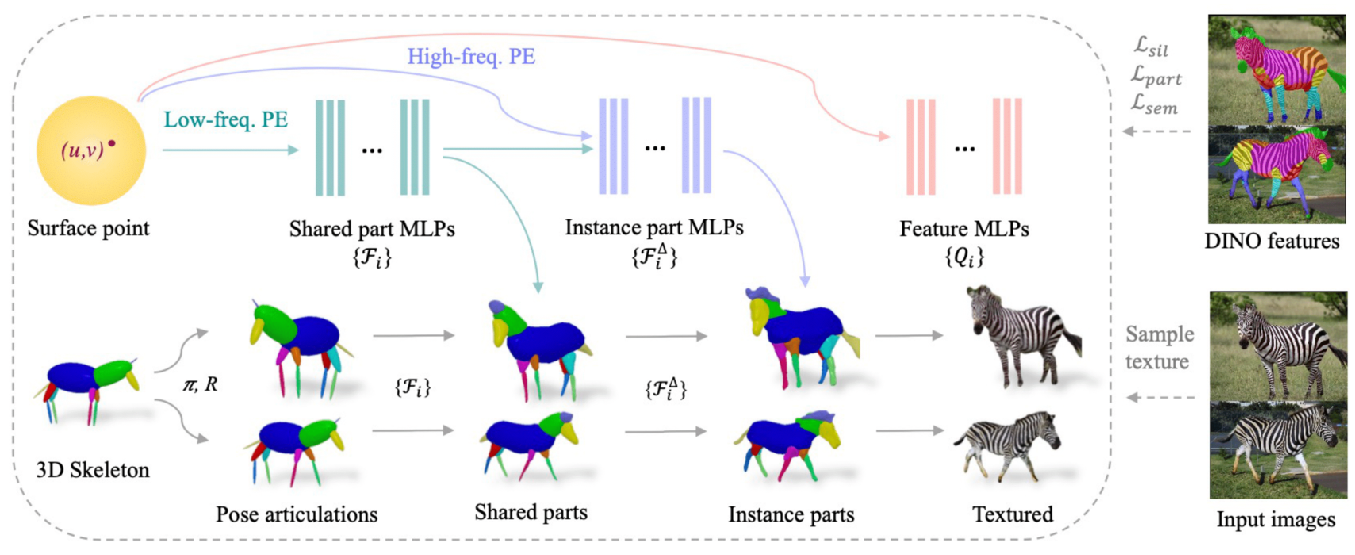
So with that, it was interesting to learn about new approaches to study animal pose and behavior without any annotations. I must admit that, to me, this is the most exciting area of computer vision for animals, as the annotation process is still wayy too laborious. As in 2021, this is still an under-represented area but I hope to see it grow more.
There were no talks on unsupervised or synthetic data approaches, but here are some posters I saw at CV4Animals and CVPR:
- Hi-LASSIE: High-Fidelity Articulated Shape and Skeleton Discovery from Sparse Image Ensemble
- From N to N+1: Learning to Detect Novel Animals with SAM in the Wild
- MagicPony: Learning Articulated 3D Animals in the Wild
- Improving Unsupervised Label Propagation for Pose Tracking and Video Object Segmentation
- BKinD-3D: Self-Supervised 3D Keypoint Discovery from Multi-View Videos
(My own contribution!!) - CLAMP: Prompt-based Contrastive Learning for Connecting Language and Animal Pose
- ScarceNet: animal pose estimation with scarce annotations

Some of this work is driven by new big models that came out in the past year. From N to N+1 (above) uses the Segment Anything Model (SAM) that came out in April 2023. SAM takes an image and a point in an image and can produce a segmentation mask. SAM works well for natural scenes, but may need to be fine-tuned for harder images experimental settings. I do think SAM will help a lot with removing backgrounds that make tracking in natural scenes challenging.

Hi-LASSIE and MagicPony build upon DINO features that came out in April 2021. As of April 2023, we now have DINOv2 features, which are even more robust and seem to work quite well on animals in natural scenes. I’m excited to see where the animal vision community will take these in the next few years.
The paper Tracking Everything Everywhere All at Once came out in June 2023. It proposes a new technique where the user specifies points in an initial image then it tracks them through a video. The Improving Unsupervised Label Propagation poster works in a similar setting, but the “Tracking Everything” method seems much more robust. I think this make it much easier to do pose estimation ad-hoc in short videos as well as reduce the need for annotation further.
Synthetic data

I didn’t see any papers on synthetic data at CV4Animals 2023. Did I miss some? Their absence seemed glaring, as these were quite popular in 2021. At the panel, someone asked what people think is the role of synthetic data going forward. The panelists seemed skeptical that it could work in the general case.
Personally, I think it could still be viable, but there needs to be an easy-to-use interface for scientists to simulate their animal of interest. Infinigen (also presented at CVPR 2023) seems like a solid step towards direction. Overall, I’m not sure whether the simulation problem is easier or harder than solving just reducing the annotation load through unsupervised and semi-supervised approaches. We’ll have to see which approach ends up being easier for scientists to apply in the next few years. Perhaps it will be some combination of these on a case-by-case basis.
New datasets
There were a bunch of new datasets at this session. In her keynote talk, Kakani Katija talked a bit about FathomNet, a crowdsourced image database of ocean creatures. There was a brief oral presentation about PanAf20K, a video dataset of ape behavior in the wild (with bounding box and behavior annotations).
Besides the above, these posters presented a variety of different datasets.
Behavior datasets:
- Meerkat Behaviour Recognition Dataset
- CVB: A Video Dataset of Cattle Visual Behaviors
- MammalNet: A Large-scale Video Benchmark for Mammal Recognition and Behavior Understanding
- PanAf20K: video dataset of ape behavior in the wild
- Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
Pose estimation datasets:
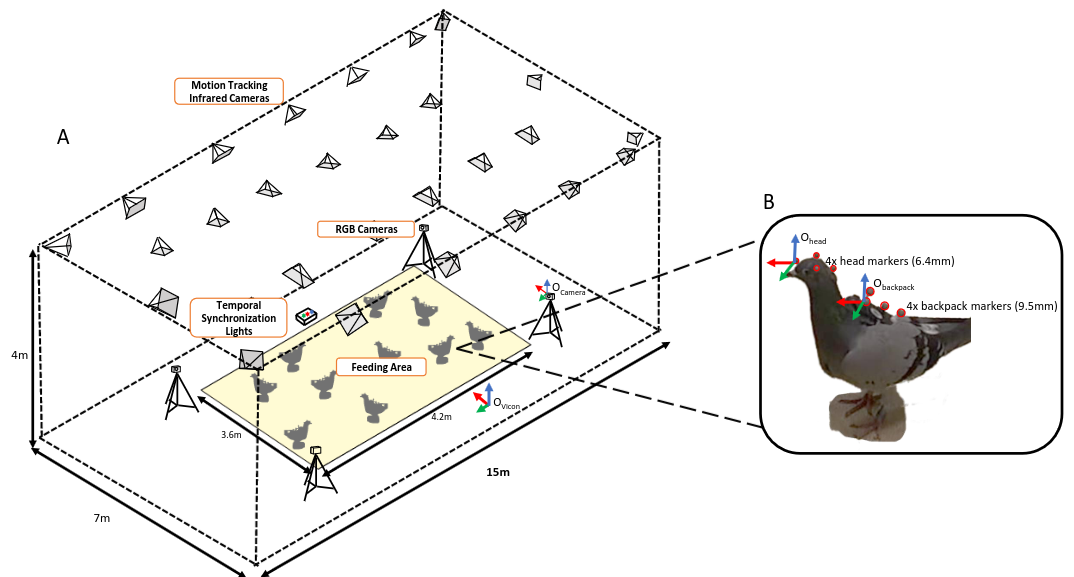
- 3D-POP - An automated annotation approach to facilitate markerless 2D-3D tracking of freely moving birds with marker-based motion capture
- CatFLW: Cat Facial Landmarks in the Wild Dataset
- PrimateFace: A Comprehensive Cross-Species Dataset and Models for Advancing Primate Facial Detection and Keypoint Analysis
Multi-animal:
- AnimalTrack: A Benchmark for Multi-Animal Tracking in the Wild1
- PolarBearVidID: A Video-Based Re-Identification Benchmark Dataset for Polar Bears
Other:
- FlyView: a bio-informed optical flow truth dataset for visual navigation using panoramic stereo vision
- AnimalTracks-17: A Dataset for Animal Track Recognition2
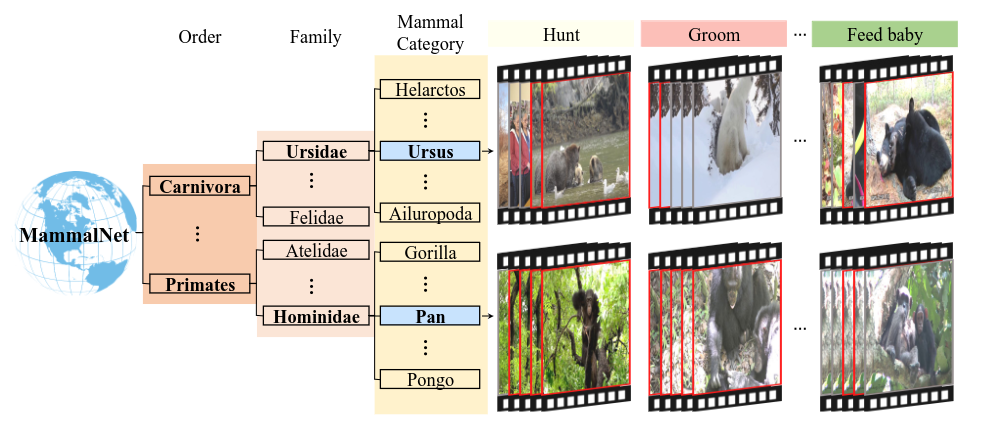
In 2021 I wrote “There aren’t the same level of datasets with animal video behavior annotations as there are for animal keypoints.” Well it’s 2023 and that has changed. We have so many animal behavior videos! The scale of MammalNet (18k videos), PanAf20K (20k videos), and Animal Kingdom (33k videos) boggles the mind. I wonder if this will usher a bigger interest in animal behavioral analysis within the computer vision community. Additionally, with unsupervised pose estimation approaches becoming useable (see above), perhaps these datasets could even be a source for understanding the fine kinematics of diverse behaviors.
Multi-animal settings and animal identification
Kostas Daniilidis started the session off with a 3D multi-animal tracking problem: cowbirds in an aviary. According to him, the multi-animal problem here is not adequately solved, but at least they did develop some nice benchmarks.
Again, here are some relevant posters:
- 3D-MuPPET: 3D Multi-Pigeon Pose Estimation and Tracking
- I-MuPPET: Interactive Multi-Pigeon Pose Estimation and Tracking
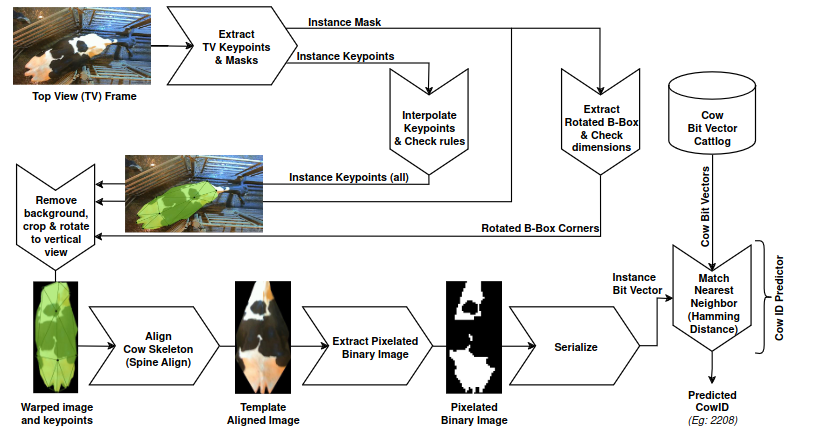
- Dynamic multi-pose, multi-viewpoint re-identification of Holstein-Friesian cattle
- Eidetic recognition of cattle using keypoint alignment
- PolarBearVidID: A Video-Based Re-Identification Benchmark Dataset for Polar Bears
- From N to N+1: Learning to Detect Novel Animals with SAM in the Wild
- Towards Automatic Honey Bee Flower-Patch Assays with Paint Marking Re-Identification3
It’s interesting to see 4 different re-identification posters, with 2 on cattle. Each method seems so different too? I don’t know what to make of the re-identification literature. Seems like a framework needs to emerge for this still.
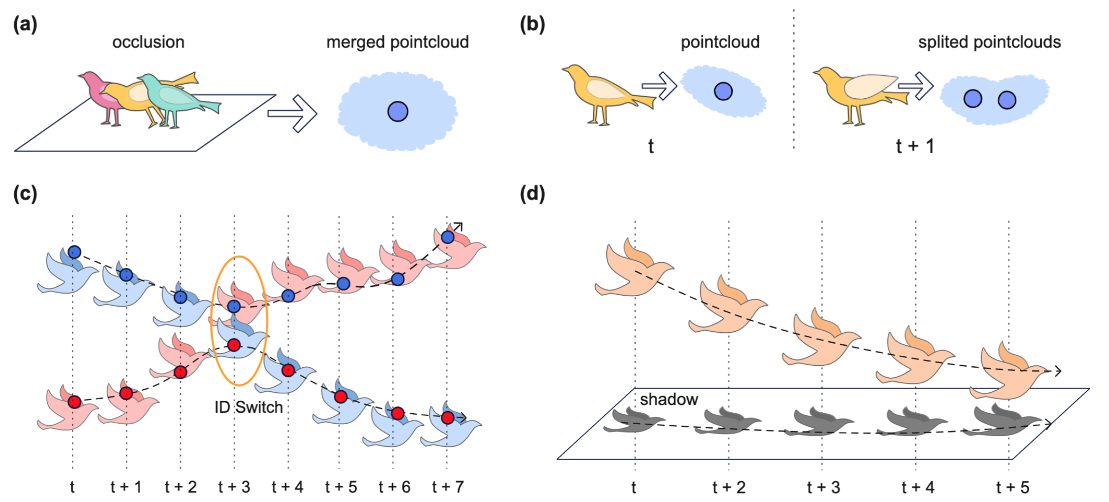
I can’t tell to what extent multi-animal tracking is solved. At least in 2D, we now have nice frameworks for doing multi-animal 2D tracking like DeepLabCut and SLEAP, but no framework is available for multi-animal 3D yet as far as I know.4 Still, as far as I could tell, nobody has even adequately solved this problem. Both Kostas Daniilidis and the authors of the 3D-MuPPET readily admitted that the multi-animal aspect in 3D still needs work. Perhaps we’ll see some new solutions at CVPR2024.
Behavior
Studying animal behavior is a huge endeavor and computer vision could really help. I saw a lot more ethologists at this workshop compared to 2 years ago. I wonder if it has to do with one of the organizers (Sara Beery) working closely with ethologists.
There were also a bunch of behavior datasets, which I reviewed above.
There were a lot of behavior papers, so I further subdivided them into multiple categories here.
Behavioral embeddings
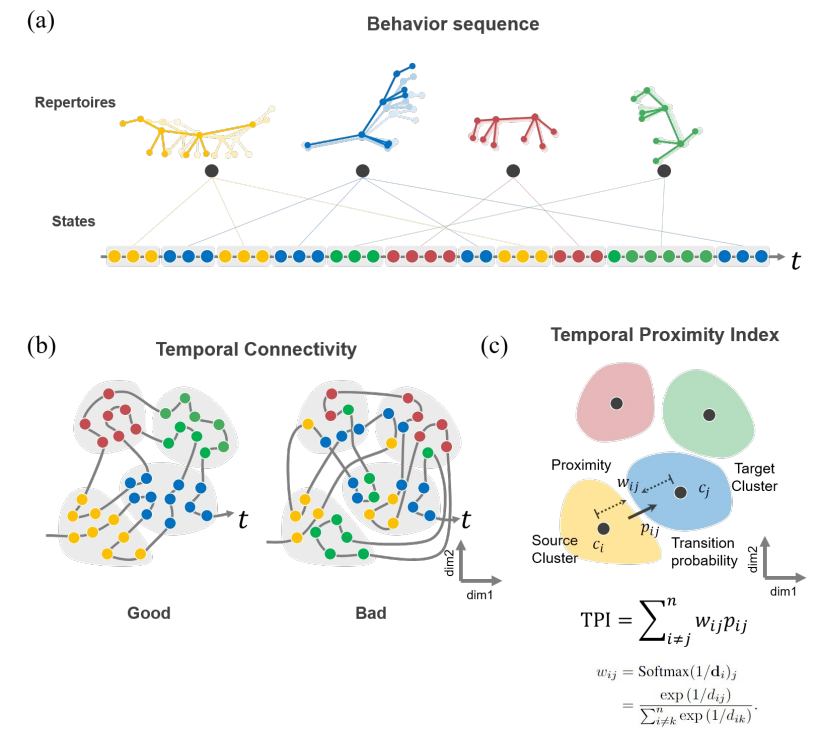
(b) They take the perspective that the better embeddings encode behaviors that are closer in time also closer in space.
(c) To quantify this, they propose the “Temporal Proximity Index”, which is higher when temporally-adjacent behaviors are embedded closer together.
We don’t really understand behavior and I often find human-specified behavioral categories reductive. For instance, there are many types of grooming for instance and each of these may occur more or less often in different environments or following different actions. Still, these are often subsided into a single category (“grooming”) for simplicity. It is hard to find a good behavioral subdivision level and maybe it doesn’t even matter for the purpose of the study. Nevertheless, the problem of finding behaviors unsupervised remains.
So… what if we could somehow get some embeddings on behavior without human input on what the behaviors actually are? These posters try a few different ways to obtain these embeddings:
- SUBTLE: An unsupervised platform with temporal link embedding that maps animal behavior
- Inverse Reinforcement Learning to Study Motivation in Mouse Behavioral Paradigms
- Hierarchical Characterization of Social Behavior Motifs using Semi-Supervised Autoencoders5
I particularly liked the SUBTLE poster, mostly because they designed a metric to evaluate behavioral embeddings based on UMAP and tested a few different hyperparameters to see what worked best. These kinds of embeddings have been pretty common in the literature (e.g. the embeddings in the Anipose and DANNCE papers are based on UMAP as well), so this evaluation felt quite relevant.
Behavioral monitoring
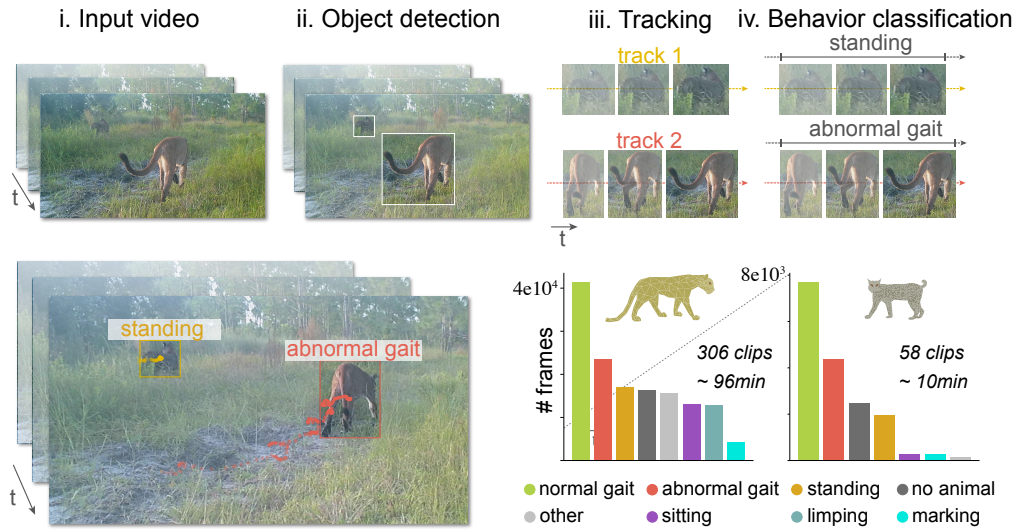
Another aspect of behavior that I saw was the idea of monitoring behavior in the wild using computer vision. This promises to scale up the analysis from camera traps and perhaps speed up interventions to help the wild life.
- Automated detection of an emerging disorder in wild felids
- Automated Video-Based Analysis Framework for Behavior Monitoring of Individual Animals in Zoos Using Deep Learning - A Study on Polar Bears
Detecting a gait disorder in wild cats was particularly interesting to me, as I thought it was a particularly cool and motivated application of computer vision. Help those poor cats!
Multi-animal behavior
Finally, I also saw a few posters focused on modeling behavior in multiple animals. A few were directly fom videos, which I thought was particularly interesting. This does feel like a sub-field to watch in the next few years. Animal behavior in the wild often naturally includes interactions across multiple animals, so having a way to quantify it would push the frontier of natural behavior analysis.
- Automatic Labelling and Characterisation of Behaviours in Group-housed Mice using a Behaviour Model across Cages
- Quantifying the movement, behaviour and environmental context of group-living animals using drones and computer vision (also vision in the wild)
- Bridging cognitive, statistical, and neural descriptions of multi-agent bird foraging behavior
- Hierarchical Characterization of Social Behavior Motifs using Semi-Supervised Autoencoders6
{kind=link}
Animal wellness

One topic that stood out to me was animal wellness, specifically detecting pain of animals from images and videos. I hadn’t really thought to apply computer vision for this purpose before.
Featured as a keynote speaker was Albert Ali Salah, who presented his work on detecting horse pain from images and dog pain from videos.
There were also a few posters from Anna Zamansky’s group:
I think this is quite a promising area for computer vision application actually. For one, using the standard scales for rating pain in animals seem quite time consuming for animal care specialists. Second, it’s possible there might be some better signals of pain that we are currently missing, that a computer vision algorithm could pick out.
The ground truth can be somewhat messy though. The ground truth here is based on whether an animal is in pain from an operation or otherwise just from human expert annotations. It’s definitely not perfect and so even the best algorithm has a limit on its accuracy…
Footnotes
I think this was actually presented at CV4Animals 2022, but I happened to come across it while trying to find the “AnimalTracks-17” dataset and figured I’d include it here.↩︎
I couldn’t find this dataset online or a paper referencing it. I do vividly remember this poster being presented at CV4Animals though. “Tracks” here references footprints. The first author is Risa Shinoda.↩︎
I couldn’t find a link for this poster. There doesn’t seem to be a publication with this title either. The first author is Luke Meyers, if you’re looking at this and it has been published somewhere in the meantime.↩︎
I do plan to add 3D multi-animal support in Anipose over the next year. Given that the authors behind DANNCE released a multi-animal dataset, I wonder if they’re planning for multi-animal support soon as well.↩︎
Technically, this was presented at the multi-agent behavior workshop, but still at CVPR2023. I don’t have an image for this one, but the authors are Daiyao Yi, Elizabeth S. Wright, Nancy Padilla-Coreano, Shreya Saxena (all at University of Florida). They found a way to represent an embedding for each frame in a video that captures social behavior.↩︎
see footnote 5 above↩︎
Citation
@online{karashchuk2023,
author = {Lili Karashchuk},
editor = {},
title = {CV4Animals 2023: {The} State of the Art in Quantifying Animal
Movement and Behavior},
date = {2023-06-19},
url = {https://writings.lambdaloop.com/posts/cv4animals-2023},
langid = {en}
}